机器学习应用建议
评估学习算法
决定下一步做什么
当我们遇到预测错误的情况时,我们可以:
- 增加训练样本(代价较大)
- 减少特征数量
- 增加新的特征
- 尝试用多项式特征
- 增加或减少lamda
评估假设(Evaluating a Hypothesis)
通常把数据分成两类(随机洗牌):
- Training set - 70%
- Test set - 30%
对于这两类数据集:
- 计算$\theta$ 然后使 $J_{train}(\Theta)$最小
- 计算test set的错误 $J_{test}(\Theta)$
具体 Test Set 评估:
- 线性回归-test set的代价函数J
- 分类问题:
a.代价函数
b.错误分类比
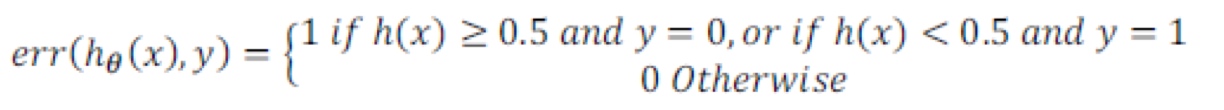
模型选择 - 训练/验证/测试
多项式的模型用在train set的结果往往比较好, 但不一定好用在test set上。
把数据集分成3类:
- 60% 训练
- 20% 交叉检验(cross validation)
- 20% 测试
方法如下:
- 用train set找到每一个多项式最佳的$\theta$
- 找到交叉检验中 test error最小的多项式
- 最后用test set得出推广误差
Bias & Variance
诊断 Bias 还是 Variance
高bias - 欠拟合
Train和CV的cost function都很高并且相近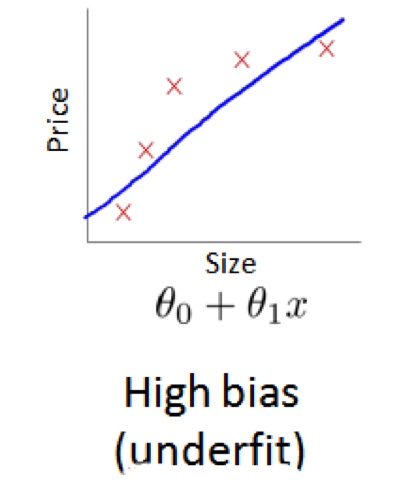
高Variance- 过拟合
Train的cost function偏低,但是cv的cost function远大于train的。
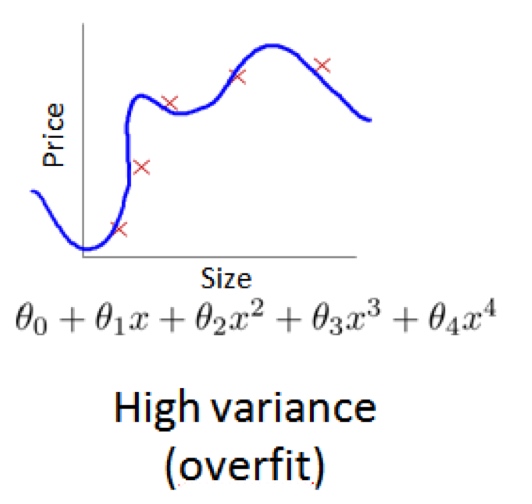
对于训练集,当 d 较小时,模型拟合程度更低,误差较大;随着 d 的增长,拟合程度提高,误差减小。
对于交叉验证集,当 d 较小时,模型拟合程度低,误差较大;但是随着 d 的增长,误差呈现先减小后增大的趋势,转折点是我们的模型开始过拟合训练数据集的时候。
归一化 和 bias/variance
lamda越大- 高bias
lamda越小 - 高variance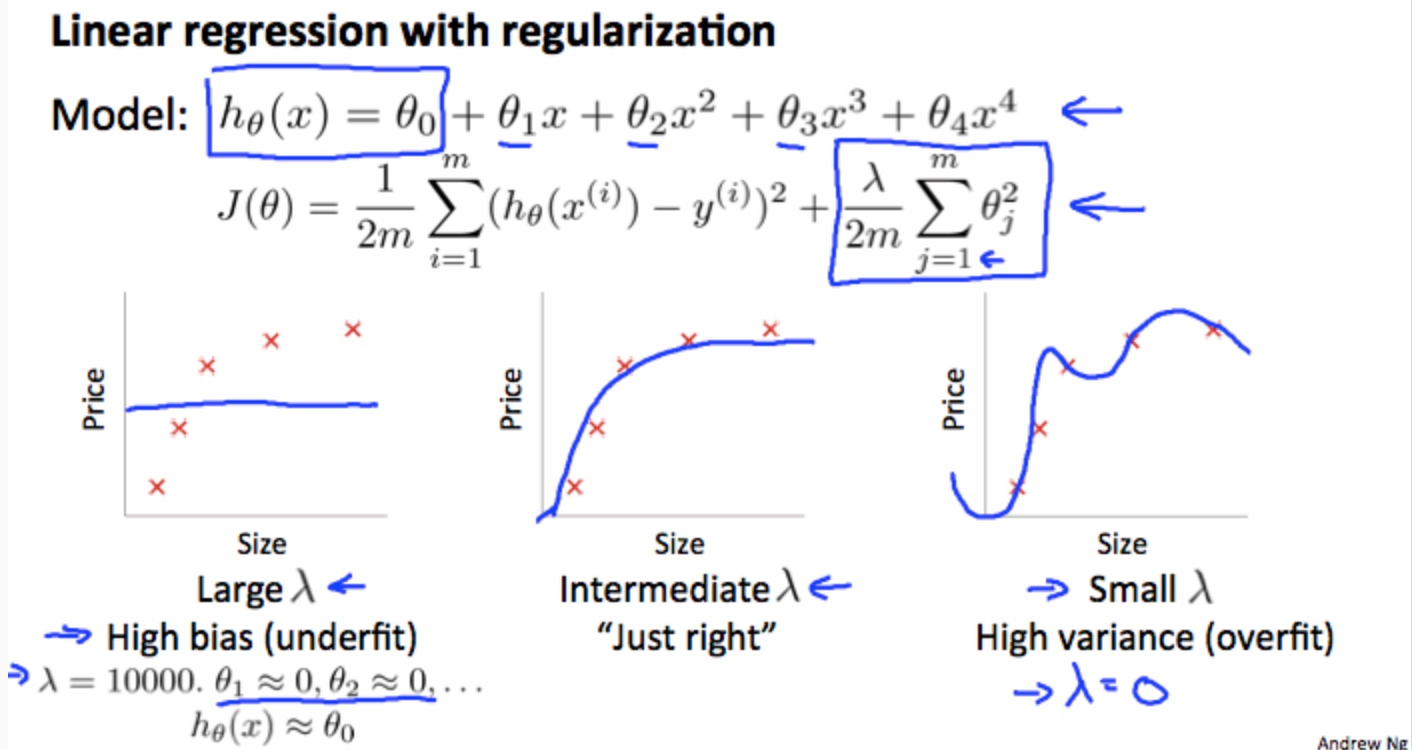
lamda通常是在0-10中测试呈现 2 倍关系的值(如:0,0.01,0.02,0.04,0.08,0.15,0.32,0.64,1.28,2.56,5.12,10 共 12 个)
学习曲线 (Learning Curve)
学习曲线是学习算法的一个很好的合理检验(sanity check)。学习曲线是将训练集误差和交叉验证集误差作为训练集实例数量(m)的函数绘制的图表
High Bias/ Underfit 提高数据量不会改变误差率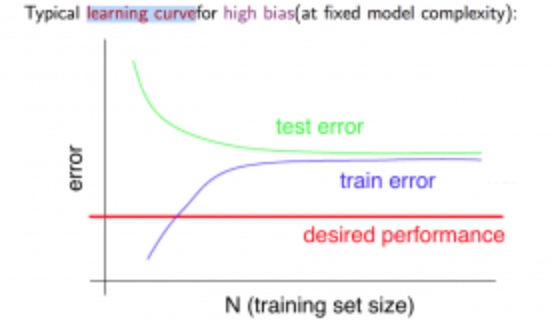
High Variance / Overfit 提高数据量能提高效果
下一步做什么
- 获得更多数据量 - high variance
- 减少特征数量 - high variance
- 增加特征数量 - high bias
- 增加多项式 - high bias
- 增加lamda - high variance
- 减少lamda - high bias
神经网络中- 参数越大-high variance过拟合。 通常使用大参数和归一化的模型。
通常从一层开始,增加hidden layer查看效果。
机器学习系统设计
首要工作
例子: 垃圾邮件分类器
我们首先要做的决定是如何选择并表达特征向量 x。我们可以选择一个由 100 个最常出现在垃圾邮件中的词所构成的列表,根据这些词是否有在邮件中出现,来获得我们的特征向量(出现为 1,不出现为 0),尺寸为 100×1。

- 获取更多的数据
- 开发更复杂的特征 (邮件的开头)
- 开发算法(检查错别字)
误差分析 (Error Analysis)
- 简单的算法, 并用cross validaiton测试结果
- 绘制学习曲线,判断是否需要更多的数据
- 手动检查错误,是否有trend
用单一标准量化错误能帮组你更好的改进模型的方法
处理偏差数据
在这种偏差很大的数据集里, 我们不能直接用accuracy来衡量结果
实际结果 : True /False
预测结果: Positive / Negative
Precision = TP / (TP + FP)
在我们预测postive的结果中的正确率
Recall = TP / (TP + FN)
在所有true的结果中,我们预测中了多少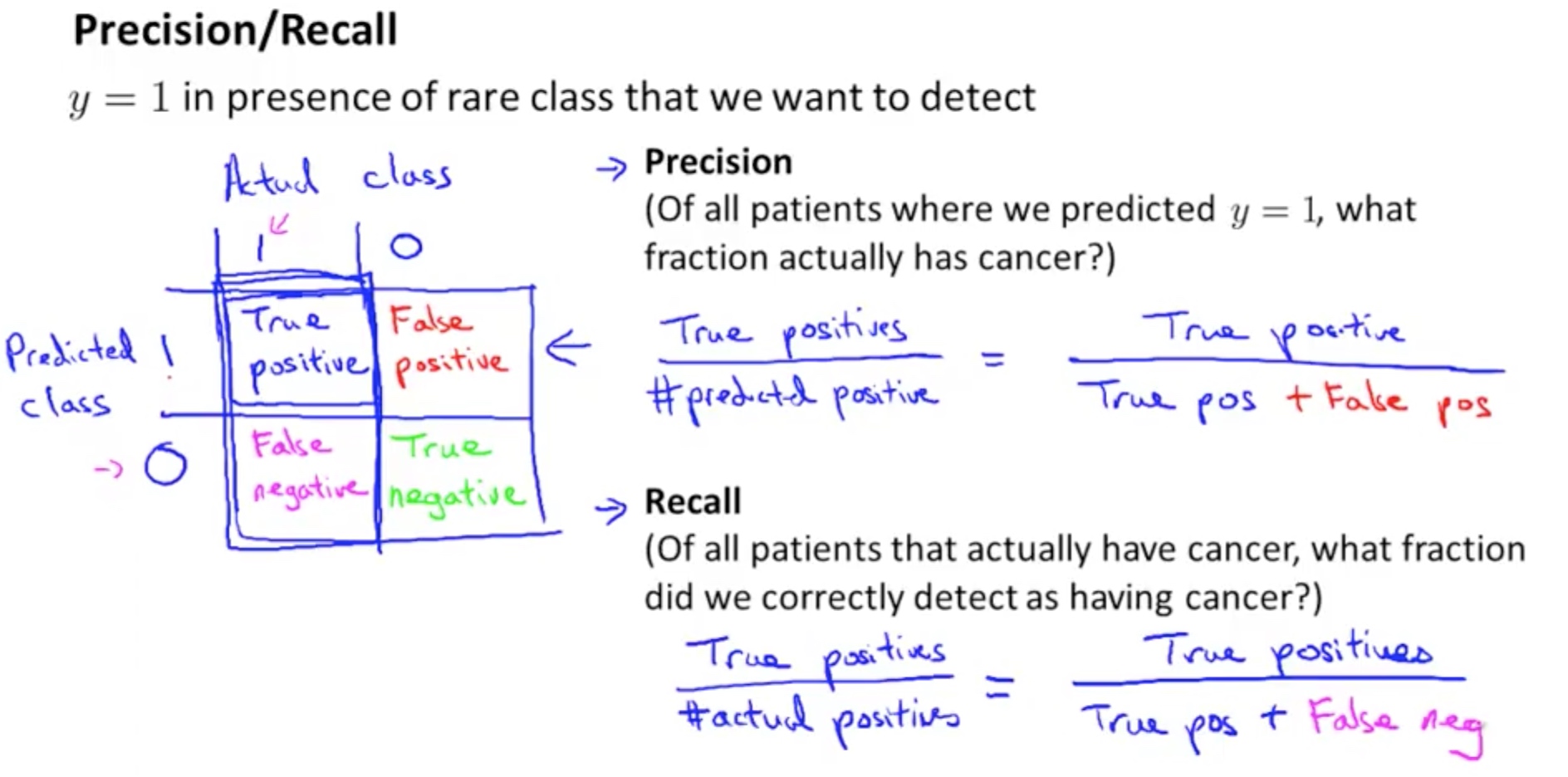
Precision 和 Recall 的权衡
通常在判断结果中我们会计算一个概率然后用到阀值cut off来判断结果的取向。
如果cut off越大, 我们的Precision正确率会高,但是Recall查全率会下降。
这时候我们会引进一饿F1 score来衡量这两者的关系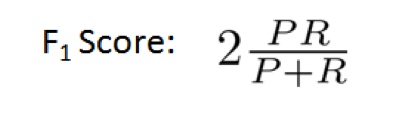
然后选择F1score最大的阀值