分类(Classification)
模型简介
输出: symbolic
输入: numeric, symbolic ,mixed
适用范围: 医院诊断病情
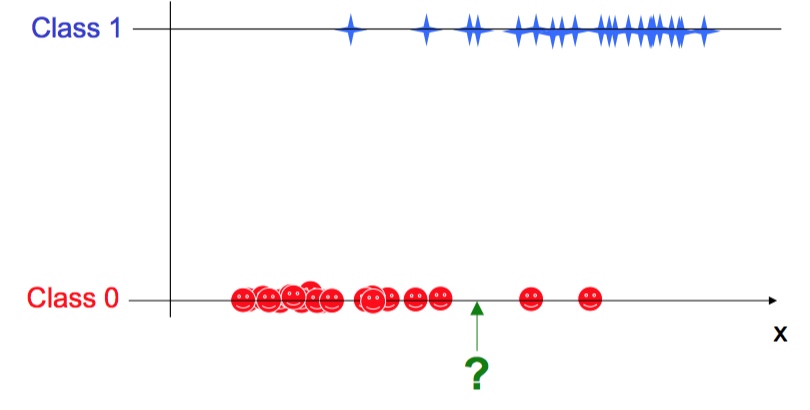
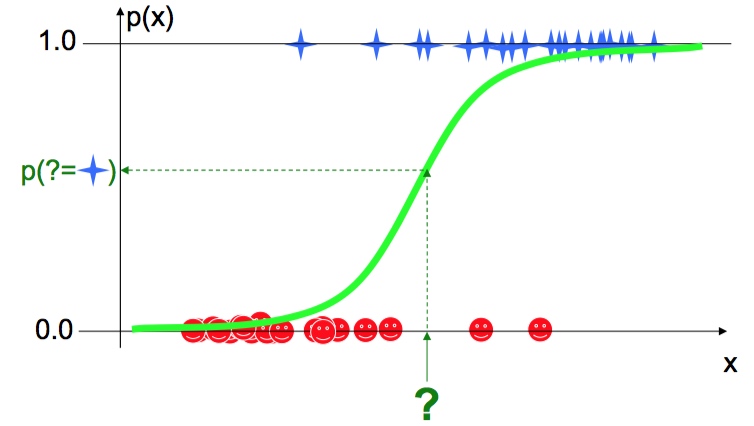
我们想知道 “?” 到底是红笑脸还是蓝星星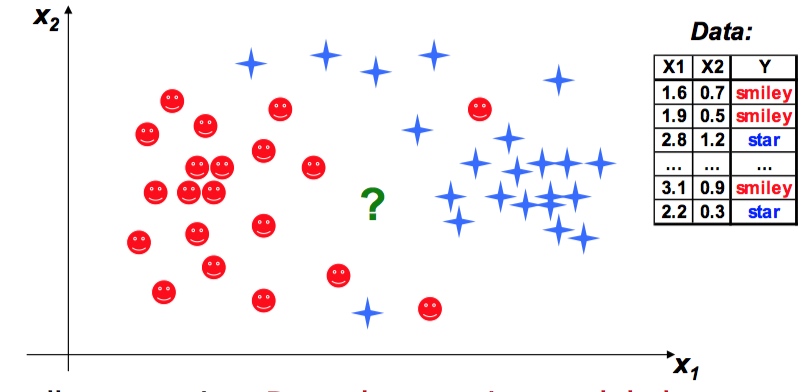
方法一 贝叶斯分类(Bayes’ classifiers)
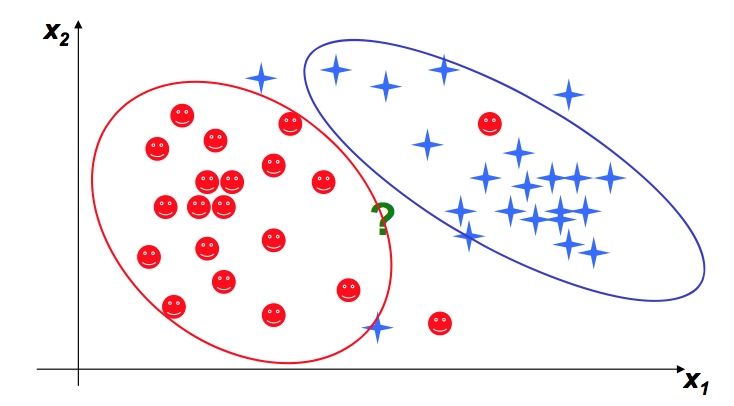
从中心出发,多少sigma范围内属于一类
方法二 Discriminative approaches
Logistic Regression (下图黄线)
Support Vector Machines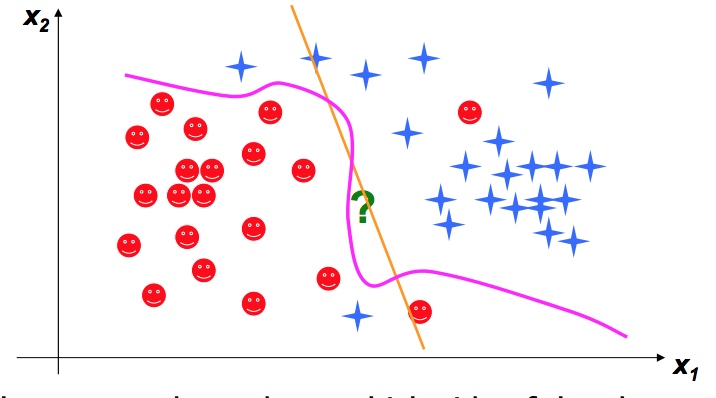
方法三 Instance-based approaches
方法四 Symbolic approaches
Decision Tree
Association Rules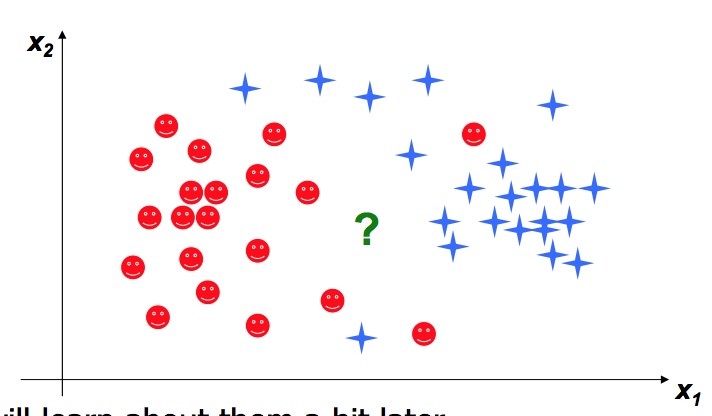
方法五 Other approaches
neural network 准确度很高,但是过于复杂取解释,有很多过拟合的情况,除非数据量足够大
贝叶斯例子(Bayes’Classifier)
目的: 捡土豆
数据: 有三样东西 土豆, 石头, 粘土
方法: 有sensor知道直径
土豆协会给我们数据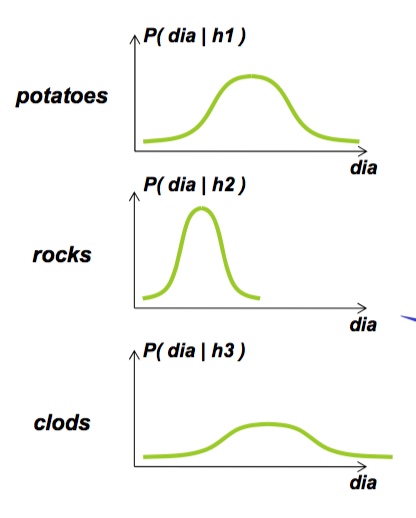
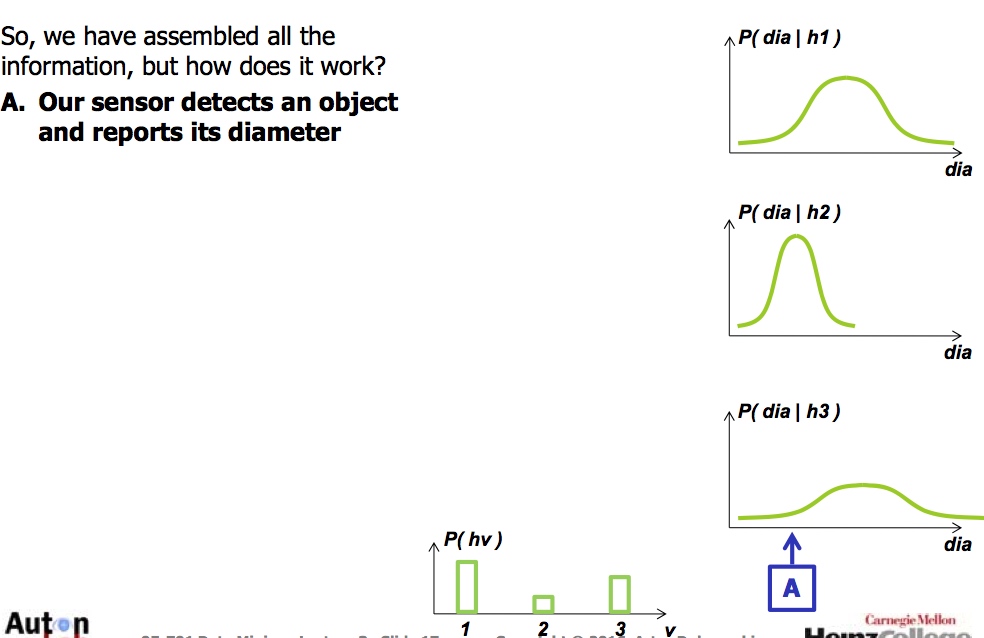
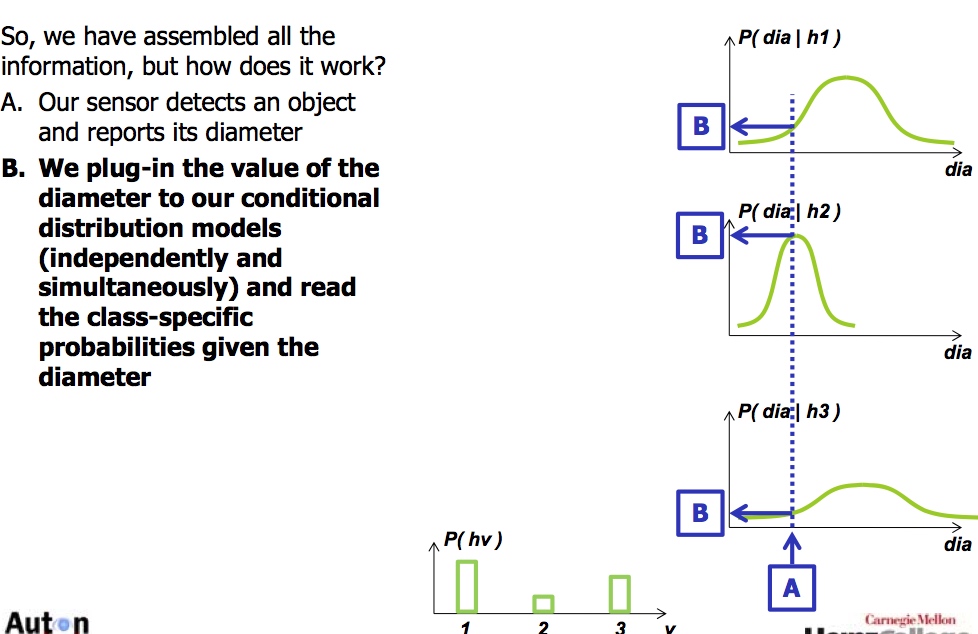
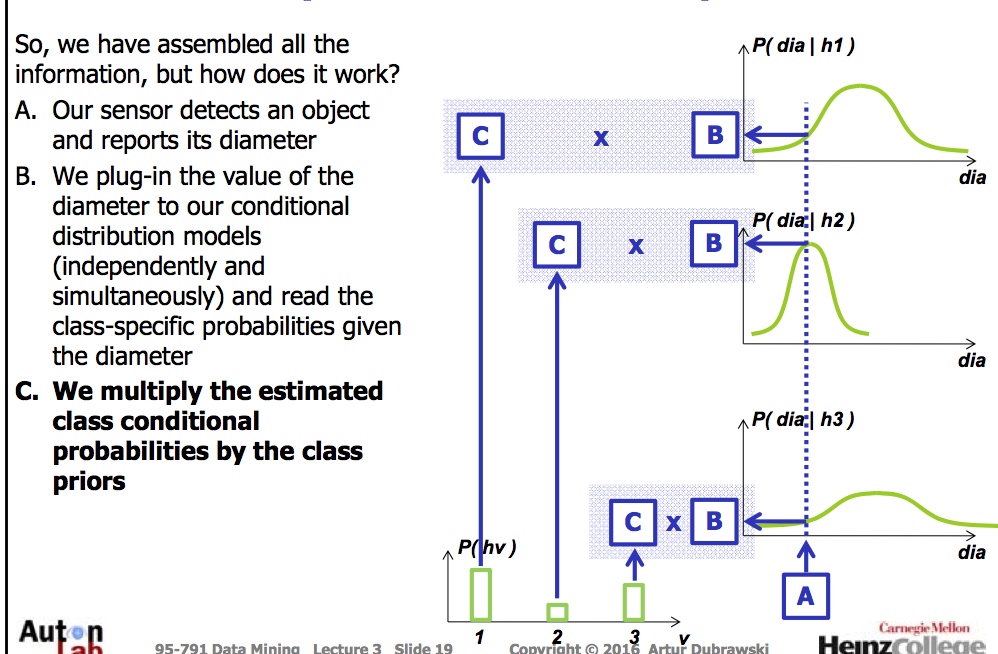
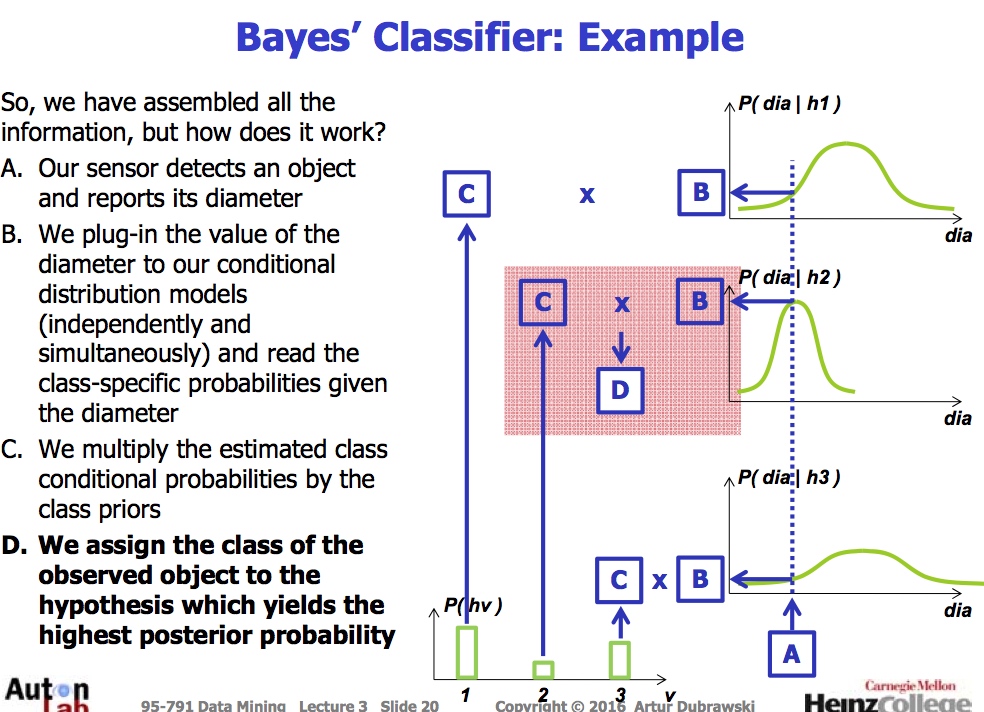
贝叶斯例子(Bayes’Classifier) 有趣点
- 不同密度的预测可以用
- 输入可以是数字或者分类信息
- 输入信息相互独立, Naive Bayes忽略了输入信息的相互关系, 好处dimension可以变得相当大(容易建立)
坏处
- 只能横向或者纵向分,
- 没有很多evidence
Logistic Regression
用途: binary output
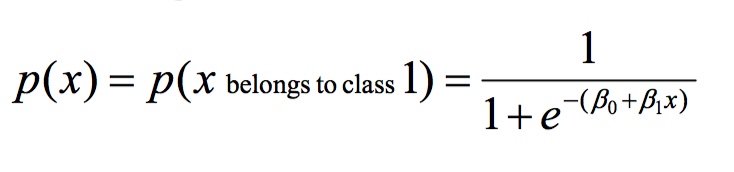
Soft Classification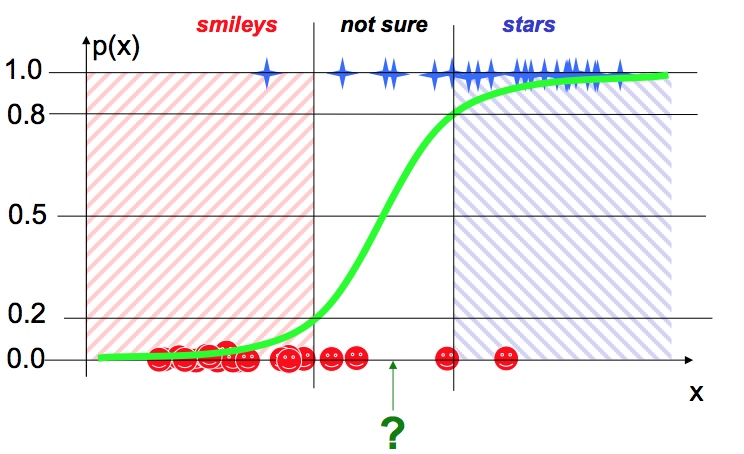
b1 决定坡度, sharper is better, easy to classify
b0 shift,左边还是右边
好消息:
efficient
容易增加dimension
- 直线(分成两部分)
用处:
- 用所有的features
- 用每个feature做独立的模型
- step -wise
如果不是线性风格?
我们可以用kenerl多元风割
Support Vector Machines
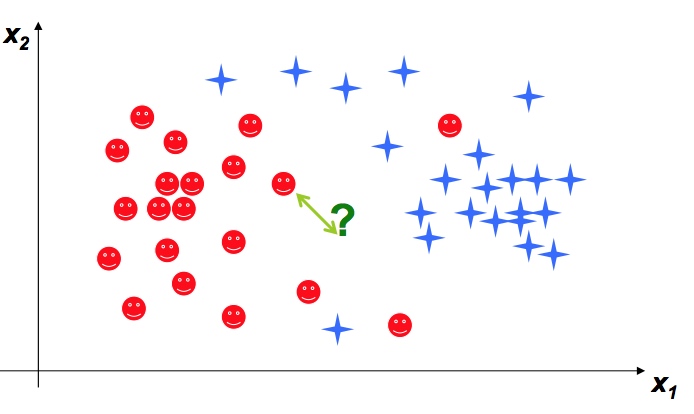
Nearest Neighbor classifier
检查它最近的邻居,分成和它邻居一样的类
如果数据很大,我们会检查所有的距离
K nearest Neighbors(K-NN)
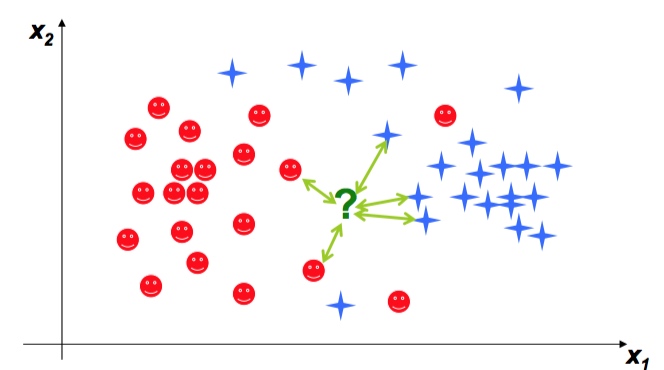
k farthest neighbors? find what is unlike us?
K_NN to non-binary problems? nothing
NN to perform regression? YES 1. find neighbor 2.what neighbor represent?(calculate avg of neighbor values)