RC1
改变Rstudio格局 Tools->Global Options->Pane Layout
|
|
HW1
这次作业的主要目的是我们为一家房地产中介提供数据挖掘咨询。 我们的产品是自动化房屋估值系统。
问题一
要求:
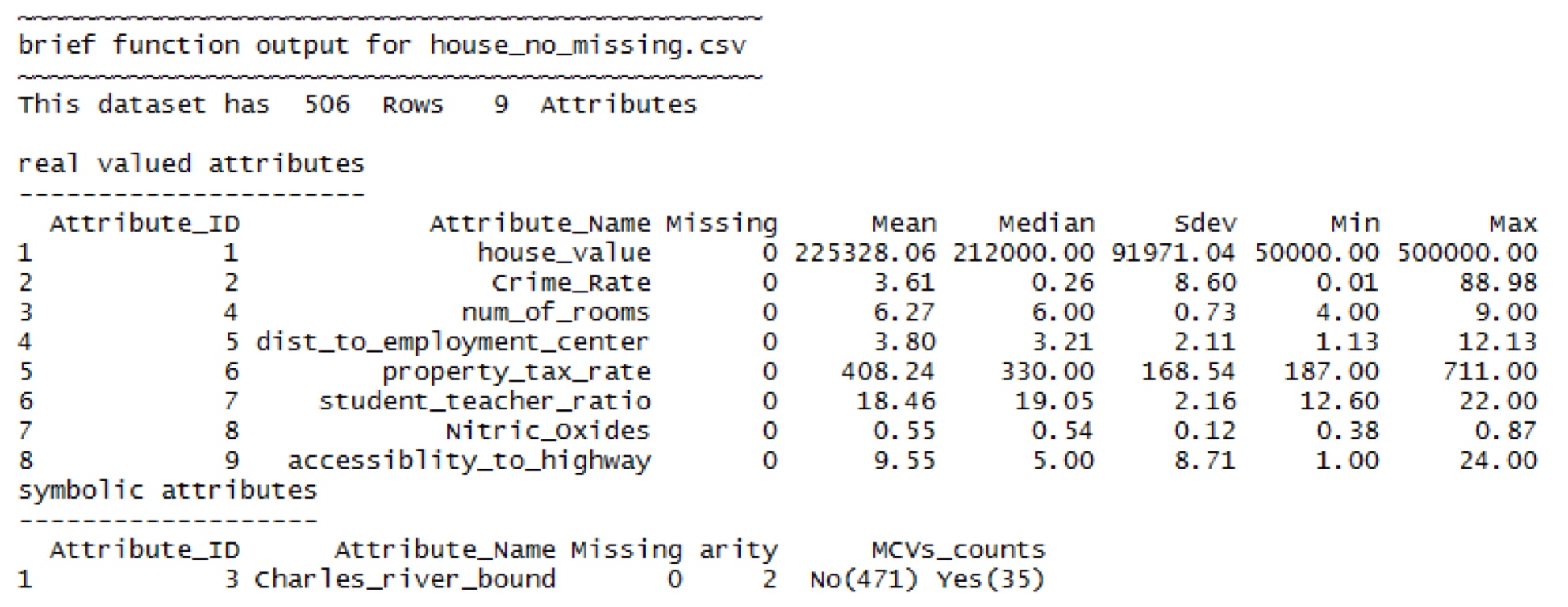
用R写一个function能够自动简单分析当前的数据集
- 输入:dataframe
- 输出:text (模版如下)
分析:
- 根据模版,我们需要把数据分成real value和 symbolic两者分别分析。
区分数字还是分类信息:
|
|
- 为了使格式整洁,我们可以用一个dataframe来存结果
|
|
- 分类信息的归纳; 唯一的难点如何对一个列的频率排序
|
|
问题一b
要求:
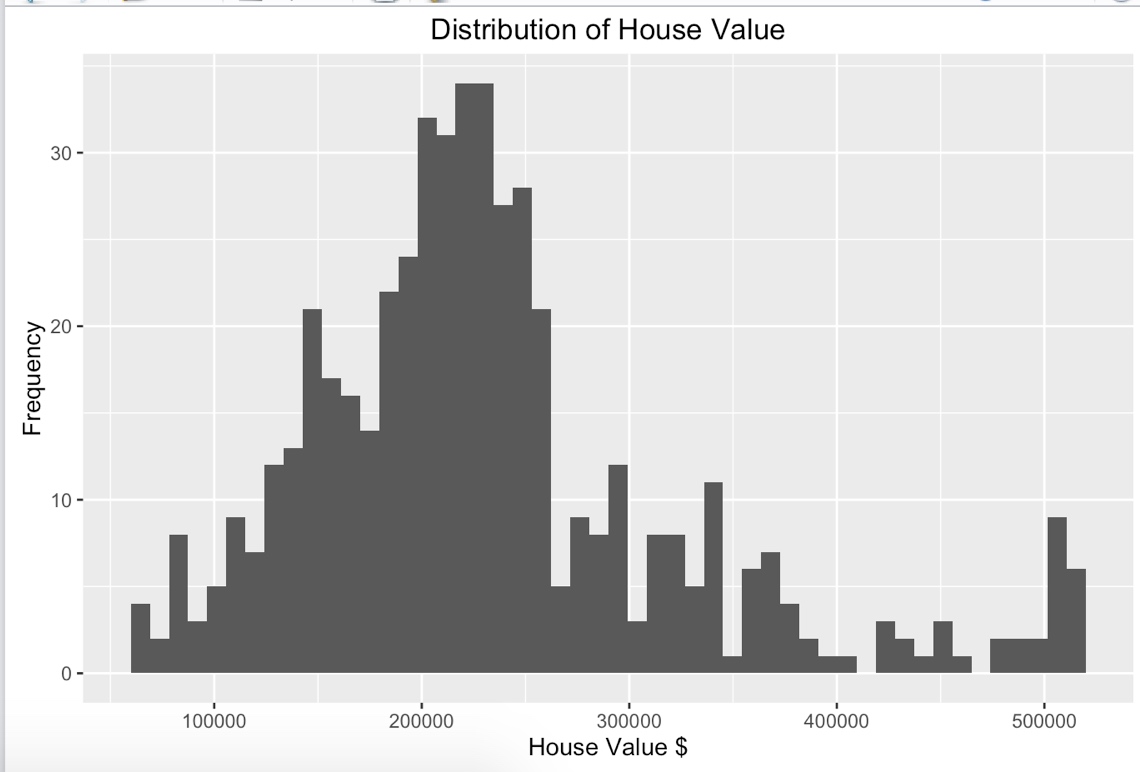
给我们客户展示一下数据集的内容:
- 一个变量分布
- 鉴于一个变量上的一个变量分布
- 一对变量的关系
分析:
考察我们作图能力,这里选用GGPLOT2,因为相比其他作图包,它是object oritended设计的,方便我们添加删除和改变
|
|
问题二
要求:
写一个function做k次交叉验证,模型有三种:
- connect-the-dots
- default predictor
- linear
输入: dataframe, k, 目标变量
输出: 一个含k个MSE得分的向量
分析
我们先要理解模型,
- connect the dots:(KNN近邻算法)
KNN根据某些样本实例与其他实例之间的相似性进行分类。特征相似的实例互相靠近,特征不相似的实例互相远离。因而,可以将两个实例间的距离作为他们的“不相似度”的一种度量标准。
KNN算法不仅可以用于分类,还可以用于回归。通过找出一个样本的k个最近邻居,将这些邻居的属性的平均值赋给该样本,就可以得到该样本的属性。 - default predictor (0次多项式回归)
- linear (线性回归)
交叉验证:
- 把目标列移到最后
- KNN不接受category变量,所以要线剔除
- 随机变化一下dataset
- 分成k段
- 每一段用作test,并计算出MSE,保存到结果
问题二b
要求:
- 用 log(crime_rate)来预测房屋价格
- 计算每一个模型的95%置信区间
分析:
没什么太大难度,只需要会使用barplot2即可