第二章 如何找寻可靠的模型
I. 数据类型
- 数字型
- 类型
- 顺序型
II. 基本模型
预测分析模型
回归模型(Regression)
- 输入-数字型, 输出-数字型
- 方法: 线性, 非线性, 多重, 无变量, 神经网络
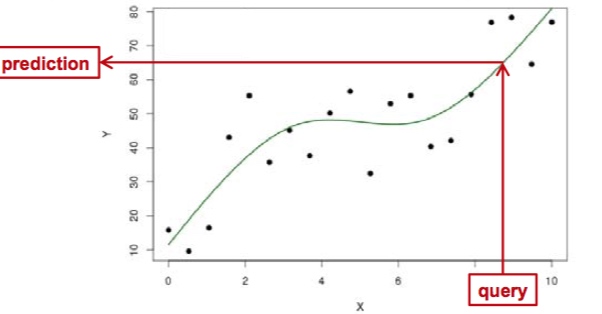
分类模型(Classification)
- 输入-标记,数字,综合, 输出-标记

2. 描述分析模型
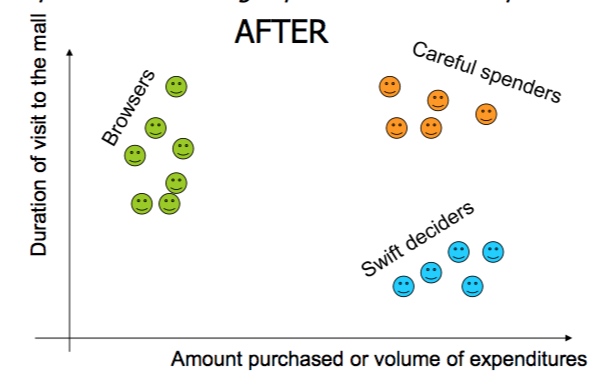
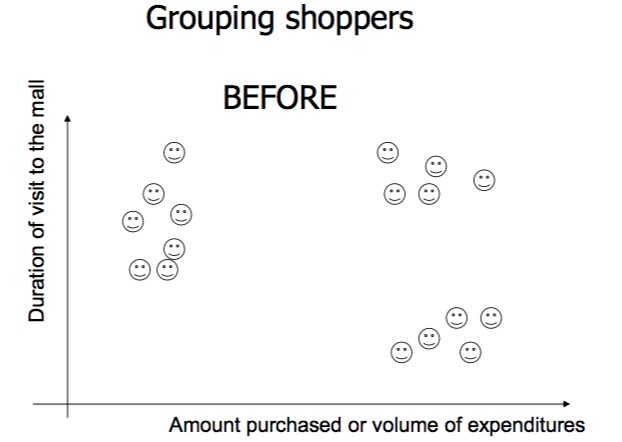
聚类模型(Clustering)
- 输入-标记,数字,综合, 输出-无
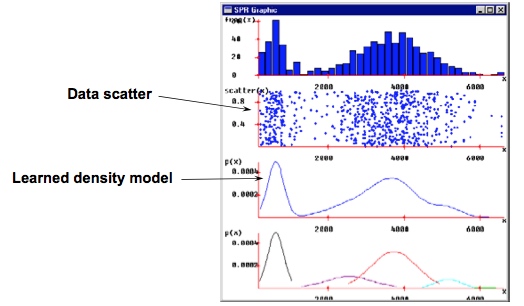
核密度估计(Density Estimation)
- 输入-标记,数字,综合, 输出-无
构造学习(Structural Learning)
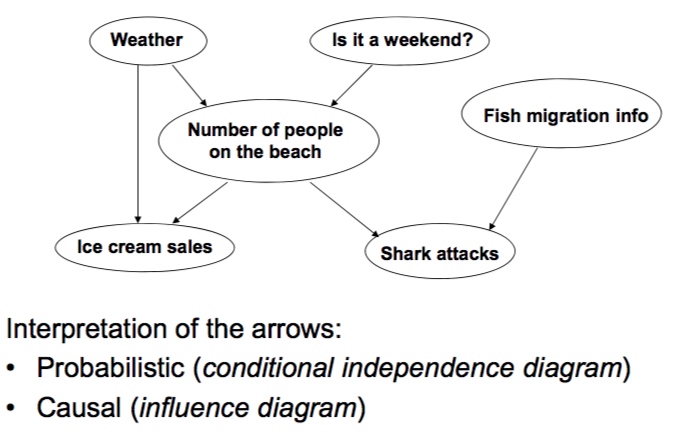
总结

III.学习的类型
监督学习(Supervised Learning)
适用于回归, 分类
非监督学习(Unsupervised Learning)
适用于聚类, 核密度估计
半监督学习(Semi-supervised Learning)
数据有些有输出值
增强学习(Reinforcement Learning)
适用于优化和控制问题
模型架构类型
1.变量模型
假定:模型符合一定的函数形式
2.非变量模型(memory-based)
记住所有训练集
正规化(Generalization)
如何数量化正规化结果?
留一些测试数据
根据测试数据预测模型拟合度
正规化曲线
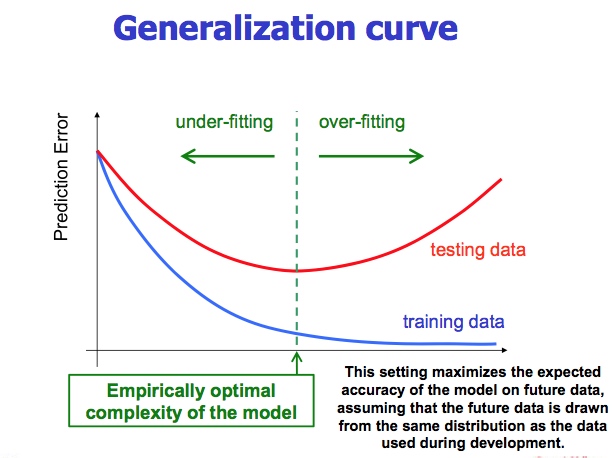
如果什么都没学到,这张图记住就好。
古话说:过犹不及。你模型训练的太好,在实际使用中效果会没有什么用
衡量模型正确性参数
预测误差(Prediction Error)


SSE 最简单粗暴
MSE 可以或略outlier因为取得是平均
RMSE 可以了解不同模型的离散程度
MAE 因为取绝对值,可以衡量平均误差大小
如何找到合适的模型复杂度
- 最简单:常量 y = b
- 线性回归(Linear Regression)
- 二次回归(Quadratic Regression)
- 多项回归(Polynomial Regression)
并不是越复杂越好,因为会过拟合(over-fit)
如何避免过拟合
检查并设置(Test&Set)
- 随机数据点
- 把数据分成两块:训练, 验证
需要考虑怎么分?
- training set中样本数量必须够多,一般至少大于总样本数的50%。
- 两组子集必须从完整集合中均匀取样
交叉验证(Leave-One-Out Cross Validation)
- 每个样本单独作为验证集
- 其余的N-1个样本作为训练集
- 循环之前的过程
- 选一个指标然后把所有模型结果放在一起比较
好处:
- 每一回合中几乎所有的样本皆用于训练模型,因此最接近原始样本的分布
- 实验过程中没有随机因素会影响实验数据,确保实验过程是可以被复制的
K组验证(K-fold Cross Validation)
- 将原始数据随机分成K组(一般均分)
- 将每个子集数据分别做一次验证集
- 其余的K-1组子集数据作为训练集
- 加总结果
现实使用
- M中模型和变量
- 使用同样的交叉检验
- 发现最好的模型
- 使用所有数据完成最终模型
复习
True or False
- In 10-fold Cross-Validation, we are splitting data into 10 disjoint subsets and use each of them for testing exactly once.
- In 10-fold Cross-Validation, we independently build 10 models using training subsets of data, and select for deployment the one that performs best on the testing subset of data.
- We use 10-fold Cross-Validation to empirically quantify the expected performance of different types of models and/or their alternative configurations.
As soon as we identify the most suitable model type and configuration, we can re-train it using all available data and then transition the result to practice.
答案:
- True
- False
- True
总结
- 用交叉检验发现好的模型
- 模型选择(ROC)
- 其他模型测试方法
你应该知道
- 数据类型
- 模型类型和区别
- 基本模型学习
- 如何衡量预测准确性
- 为什么偏好正规化的模型
- 什么是过拟合,如何规避
- 交叉检验如何使用